Shur Creative Partners · Internal Prep
The topology map needs a sidebar.
Closing Gap 03 from the 2026-04-22 post-call analysis: ShurIQ's topology map is internally cherished but externally quizzical without explanation. This is the V3 grammar prep — the caption template, the worked examples, and the five open questions for the meeting with Diana and Nuri.
What the caption is for
Three jobs, in order:
- Tell the reader what they are looking at — cluster topology, not a flow chart.
- Tell them how to read it — color is cluster, size is betweenness, edges are co-occurrence.
- Surface the one strategic insight that makes this map worth reading for this report.
Diana's framing from the April 22 transcript (line 315) — the magazine analogy:
When you're in a magazine, there's something complicated, there's an infographic, but there's a little explanation. Our brains are so trained to ingest information this way.
Template
<aside class="topo-aside">
<h5>Reading the map</h5>
<p><!-- WHAT --></p>
<p>Each circle is a {{NODE_DEFINITION}}; size scales with
{{SIZE_METRIC}} — {{SIZE_METRIC_PLAIN_LANGUAGE}}. Color groups
indicate clusters: {{CLUSTER_LEGEND}}.</p>
<p><!-- HOW --></p>
<p>The heaviest gateway{{S}} — {{TOP_NODES}} — {{GATEWAY_DESCRIPTION}}.
{{SECONDARY_NODE_COMMENTARY}}</p>
<p><!-- WHY (this report) --></p>
<p>{{ONE_INSIGHT}}</p>
</aside>Worked examples
From the deployed Fiserv GTM brief
Reading the map
Each circle is a concept that surfaced in the conversation; size scales with betweenness centrality — how often a concept bridges two otherwise-separate topics. Color groups indicate clusters: cobalt for brand dimensions, warm for design archetypes, red for grammar insights, violet for topology & tools, green for navigation & reader-mode.
The two heaviest gateways — brand (BC 0.32) and design (BC 0.30) — are co-dominant. The call was structurally about how brand intelligence flows through the design system. Lens (BC 0.18) emerges third, connecting competitive analysis, gap analysis, and dimensional scoring.
The Brooks/Nike/Figs cluster (lower right) is the Pivot Thesis future module Nuri surfaced — small in volume but conceptually consequential.
Pressure Test variant — defensibility-weighted
Reading the map
Each circle is a concept; size scales with betweenness centrality. Color = cluster.
The map is the audit trail for [SECTION_BEING_DEFENDED]. [TOP_NODES] are the gateway concepts the analysis rests on; if the data underneath these nodes is challenged, the gap analysis above [paragraph X] needs to be re-stated. [SECONDARY_NODES] are corroborative — they confirm the pattern without being load-bearing.
Inference vs. observation: nodes labeled with [convention TBD] are direct observations; unlabeled nodes are inferred from co-occurrence frequency.
Cold Read variant — hook-tuned
Reading the map
Each circle is a concept that came up when we looked at [your category / your competitive set]. Size = how connected; color = cluster.
[TOP_NODE] is the gateway. The pattern around it is [ONE_LINE_OBSERVATION_THAT_CREATES_CURIOSITY].
Worth a longer conversation: [SPECIFIC_NODE_OR_CLUSTER] looks structurally [thinner / denser / mismatched] than we'd expect for a [VERTICAL_TYPE] of your size.
Style rules
| Rule | Reason |
|---|---|
| Three paragraphs maximum | Magazine sidebar discipline. Reader scans, doesn't study. |
| First paragraph defines, second describes, third points | Diana's what / how / why structure. |
| Use the cluster's semantic label, not its color name only | "brand dimensions" not just "cobalt cluster" |
| Bold the top 1–3 nodes with their BC scores | Reader's eye finds the gateway concepts. |
| Italicize the strategic insight if it embeds the Reframe | Visual signal that this is the pivot, not just a description. |
| One topology map = one caption | Multiple maps each get their own caption. |
| Caption is part of the map | Engine treats them as a single visual unit. §08 ships both or neither. |
Open questions for the V3 meeting
Five questions. Each has a recommendation; the meeting can ratify, redirect, or defer. Q3 is the one Jonny flagged as unclear — it now has a clean reframing.
Caption length cap
Three paragraphs is the rule. Should we cap word count too?
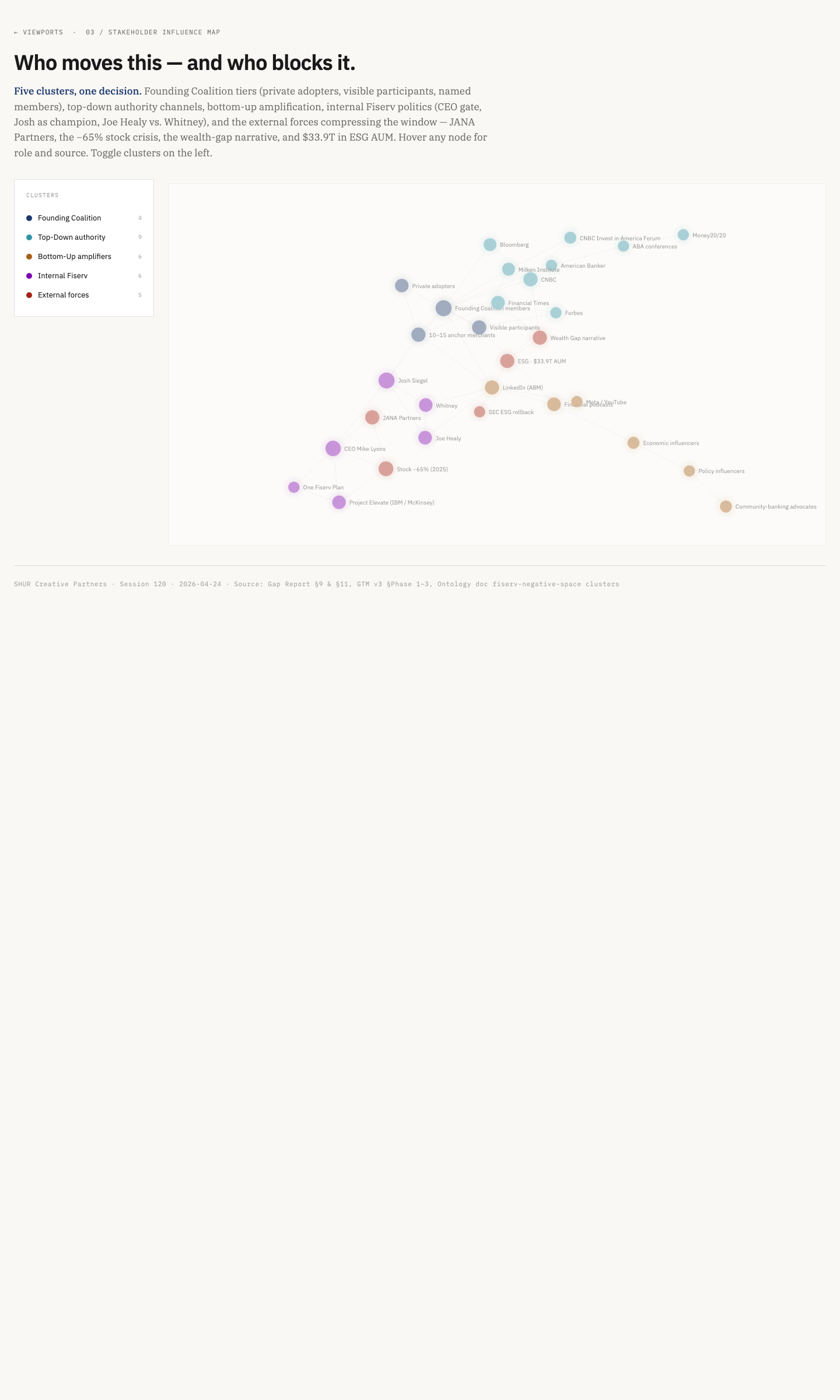
Fiserv Prosperity Viz · Stakeholder Map · sidebar caption pattern (live exemplar) · fiserv-prosperity-viz.pages.dev/03-stakeholders.html
Recommendation
80–120 words. Calibrated against the Fiserv exemplar — three paragraphs that fit alongside a 1080×800 graph without forcing scroll. Anything longer breaks the magazine sidebar pattern Diana asked for.
Caption position — sidebar vs. below-map
Sidebar is the current Fiserv convention; below-map is more magazine-traditional. Pick one or accept both?
Sidebar · right of map
Magazine sidebar discipline. Reader scans left-to-right: figure → caption. Holds at desktop (≥1024px).
Below-map · stacked
Each circle is a concept; size scales with betweenness centrality. brand (BC 0.32) and design (BC 0.30) are co-dominant. The Brooks/Nike/Figs cluster is the Pivot Thesis future module.
More magazine-traditional. Caption inherits full width and reflows. Right pattern at <1024px (tablet/mobile).
Fiserv Prosperity Viz hub · live sidebar pattern at viewport level · fiserv-prosperity-viz.pages.dev
Recommendation
Accept both, responsive. Sidebar at ≥1024px (desktop); stacks below the map at <1024px (tablet/mobile). Engine emits the same caption HTML; CSS does the rest.
Multi-viewport hubs — does the hub need a synthesis caption?
The original wording said "the AHA Pressure Test sometimes shows three overlapping maps" — that was imprecise. After re-checking the deployed pages, here is what is actually shipped:
Before · misleading
The AHA Pressure Test sometimes shows three overlapping maps — should there be a meta-caption that links them?
After · clean
When a report ships ≥3 viewports under one master narrative — like the AHA InfraNodus hub or Fiserv's Five Lenses — does the hub itself need a synthesis caption that explains why these maps belong together?
What's actually deployed
AHA Pressure Test response brief. Text-forward. Cites 5 graphs in the methodology table but does not visually embed multiple maps. The "5 graphs" appear as data citations, not visualizations.
aha-pressure-test.pages.dev · methodology section · 5 graphs cited textually, not visualized · aha-pressure-test.pages.dev
AHA InfraNodus Viz hub. Five analytical viewports, each on its own page, each with its own caption. Stats banner: 449 nodes / 1,081 edges across 4 graphs.
aha-infranodus-viz.pages.dev · 5-viewport hub for AHA strategic intelligence · aha-infranodus-viz.pages.dev
Fiserv Prosperity Viz — "Five lenses on a $233B opportunity." The closest analog: 5 viewports under one report, each with its own page and its own caption. The hub-level prose intro does some synthesis work but is a single sentence.

fiserv-prosperity-viz.pages.dev/05-negative-space.html · individual viewport with its own caption · view live
Today vs. proposed — hub-level synthesis caption
Today · no hub synthesis
Fiserv · Prosperity Initiative
Five lenses on a $233B opportunity.
Narrative architecture, campaign engine, stakeholder map, value flow, and negative-space analysis.
Tagline names the lenses but doesn't explain why they belong together or what to compare across them.
Proposed · hub synthesis caption
Fiserv · Prosperity Initiative
Five lenses on a $233B opportunity.
Narrative architecture, campaign engine, stakeholder map, value flow, and negative-space analysis.
60–100 word synthesis. Names cross-viewport pairings explicitly. Sits above the cards, not inside them.
Recommendation
Yes — when ≥3 viewports. The hub-level synthesis caption sits at the hub page (not inside individual viewport sidebars) and answers a different question than viewport captions: why look at these together, and what should the reader compare across them? One paragraph, 60–100 words, with explicit cross-viewport pointers ("Viewport 02 and 04 read together show the campaign-to-capital gap"). Keep individual viewport captions intact — they answer "what is this one." The hub caption answers "what is the set."
Cluster label sourcing
The semantic labels (brand dimensions, grammar insights, Trust cluster, Tech Gap cluster) are currently human-authored. Can the engine auto-derive them from cluster top-concepts?
shur-aha-editorial-brief.pages.dev · clusters labeled "Trust," "Loyalty," "Tech Gap," "Fundraising Impact" — all analyst-authored · view live
Today vs. proposed — cluster label sourcing
Today · human-authored
Analyst writes each label by hand from cluster top-concepts. Quality is high but throughput is low — every report is a fresh authoring pass.
Proposed · engine auto-derive + override
Engine emits label + confidence from top-3 nodes. ≥0.7 ships as auto. 0.5–0.7 ships flagged for review. <0.5 ships as Cluster N with TODO marker. Analyst override is a one-line edit.
Recommendation
Auto-derive at ~70% confidence from each cluster's top-3 nodes. A cluster with trust, mission, donor as top concepts → Trust. A cluster with data, AI, roadmap → Tech. Engine emits the auto-label with a confidence score; analyst override remains a one-line edit. Below 0.5 confidence, ship as Cluster N with a TODO marker — never a placeholder.
Cold Read hook discipline — linter or editorial judgment?
Should the strategic-insight-as-hook be enforced via a linter (no period at end, must contain question mark or curiosity verb) or left to editorial judgment?
aha-pressure-test.pages.dev hero · closed-claim style ending in a period · this is Pressure Test tonality, not Cold Read · view live
Closed-claim vs. curiosity-verb hooks
Closed-claim · linter would flag
The Trust cluster sits at the center of the brand graph and anchors every downstream engagement decision.
Ends in periodNo curiosity verb
Sounds like a finding — closes the loop before the reader's curiosity has opened. Right voice for Pressure Test (audit), wrong voice for Cold Read (wedge).
Curiosity-verb · linter passes
The Trust cluster sits unusually far from Loyalty for an org with this much donor history — worth a longer conversation.
Curiosity verb presentOpen-ended
Same observation, but framed as a question the reader leans into rather than a verdict already delivered. Hook for Cold Read.
Allowed curiosity verbs and phrases (linter whitelist): looks like · suggests · points to · sits oddly with · worth a longer conversation · the pattern around it is · or any sentence ending with ?.
Recommendation
Linter rule with editorial override. Cold Read hook must end with ? OR contain one of: looks like, suggests, points to, sits oddly with, worth a longer conversation, the pattern around it is. Linter flags violations during build; the analyst can override with a // hook-override: reason comment. The override comment ships in the build log so we can audit how often editorial judgment is invoked. If override rate >30% across 10 reports, the linter rule itself needs revisiting.
Engine integration
The strategic insight is the only field that requires human authoring. Everything else can be auto-derived from the InfraNodus graph metadata. If the strategic insight is missing, the engine ships the caption with a TODO marker — never with a placeholder.
topology_figure:
graph_id: shur-fiserv-gtm-call-2026-04-22
modularity: 0.654
node_count: 150
edge_count: 376
cluster_count: 14
top_nodes:
- { node: brand, bc: 0.32, color: cobalt }
- { node: design, bc: 0.30, color: warm }
- { node: lens, bc: 0.18, color: cobalt }
cluster_legend:
- { color: cobalt, label: "brand dimensions" }
- { color: warm, label: "design archetypes" }
- { color: red, label: "grammar insights" }
- { color: violet, label: "topology & tools" }
- { color: green, label: "navigation & reader-mode" }
strategic_insight: "The Brooks/Nike/Figs cluster
(lower right) is the Pivot Thesis
future module Nuri surfaced —
small in volume but conceptually
consequential"
reader_mode_primary: analyst
reader_mode_skim: operator # via captionCold Read special case
In Cold Read archetype, the strategic_insight field becomes the hook. It must end in a question or an observation that invites a follow-up — not a closed claim. See Q5 for the linter spec.